The Sigmoid and SoftMax functions specify the activation functions that are utilized in Deep Learning, more specifically in the field of Machine Learning, for classification techniques. The activation function modifies a neuron’s weighted sum such that the result isn’t linear.

The Sigmoid Activation Function
The mathematical function known as the “Sigmoid Activation Function” has an easily identifiable “S” curve. It is utilized for the implementation of fundamental neural networks and logistic regression. The Sigmoid Function is the best option if we want a classifier to solve a problem with more than one correct response. This function should be independently applied to each component of the raw output. The sigmoid function often returns values between 0 and 1 or between -1 and 1.
These functions come in a variety of forms. In addition to the logistic function, the hyperbolic tangent function has also been applied to artificial neurons. It has additionally been applied as a Cumulative Distribution Function. It is simple to use and cuts down on implementation time. On the other hand, the short range of a derivative has a substantial disadvantage because it results in a significant loss of information.
Read Also: Autoencoders Explained with Working
The Sigmoid Function appears as follows:
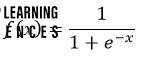
In our Neural Network, the more layers there are, the more information is compacted and lost per layer, amplifying and leading to severe data loss overall.
Therefore, if z increases to a positive infinity, the expected value of y will be 1, and if z decreases to a negative infinity, the predicted value of y will be 0. And if the sigmoid function’s result is greater than 0.5, we categorize that label as class 1 or positive class, and if it is less than 0.5, we can classify it as class 0 or negative class.
| Animal | Image1 |
| Axe | Probability: 0.7 |
| Dog | Probability: 0.8 |
From the above table, Image 1 with 0.7 and 0.8 probability will be classified as Axe and Dog respectively.
The Softmax Activation Function
The interesting Softmax Activation Function normalizes real number vectors as inputs into a probability distribution proportional to the exponentials of the input numbers. It is also known as SoftArgMax or the Normalized Exponential Function. Before applying, some of the input numbers may be negative or more than 1. Additionally, the sum might not be 1. After applying Softmax, each element will have a value between 0 and 1, and the elements will add up to 1. In this approach, they can be understood as a probability distribution. To be more precise, the chance will increase as the input number increases.
Key points are given below:
- The goal of artificial and convolutional neural networks is to convert non-normalized data output into probability distributions for output classes. It is applied to classifiers that use neural networks in their final levels. Either the cross-entropy or log-loss regime is used to train them. As a result, multinomial logistic regression with a non-linear form is the outcome (Softmax Regression).
- Naive Bayes Classifiers, for example, and other multiclass classification techniques like the multiclass linear discriminant analysis.
- Values can be transformed into action probabilities using the Softmax function in reinforcement learning.
The Softmax function appears as follows:
softmax(z_j)= (e^z j)/(∑_(k=1)^k▒〖e^z k〗) for j=1,…..k
The Sigmoid function and this are comparable. The distinction is that all of the values are added together in the denominator. To further clarify, it should be noted that while determining the value of Softmax on a single raw output, we must consider all of the output data and not just one element. The Softmax is awesome mostly because of this. It guarantees that the total of all of our output probabilities is one.
Example
Let’s explain it with an Example. Arbitrary real values can be converted into probabilities using Softmax, which is frequently helpful in machine learning. The arithmetic is quite straightforward: given a set of numbers.
- Raise each of those integers to the power of e, the mathematical constant.
- Add up each exponential (powers of ee). The denominator is this outcome.
- Use the exponential of each value as the numerator.
- Probability= Numerator/Denominator
In a fancier form, Softmax executes the following transformation on n numbers s(x_i)= (e^x i)/(∑_(j=1)^n▒〖e^x j〗)
The Softmax transform always produces outputs that sum up to 1 and fall inside the range [0, 1]. they create a probability distribution as a result. Consider the following: “-1, 0, 3, and 5”. We begin by determining the denominator:
5
“Denominator= e^(-1)+e^0+e^3+e^5= 169.87
The probability and numerators can then be determined.
The greater the x, the more likely it is. Additionally, note that the probability all sum up to 1, as was previously stated.
| Animal | Probability |
| Axe | 0.988 |
| Cat | 53.00 |
| Dog | 66.99 |
Let’s suppose we want to classify Cat, Dog, and Axe images and we finally got the final probability as follows.
As the probability for Axe is maximum so the image will be classified as an Axe.
FAQs
Can many categorization problems be solved with softmax?
Yes, it is. As it acts as an activation function in neural networks. It performs its action in output nodes for multiclassification.
What is the sigmoid function’s greatest output value?
This curve, which has an “s” shape, restricts the node’s output. In that example, the sigmoid can only produce a value between 0 and 1 while accepting an input value between 0 and +.